Canvas Hit Detection
31 Mar 2011 CommentsThe Problem
When drawing graphics with SVG or VML, it’s easy to detect when a user’s mouse (or finger) hits a feature because we’ve got DOM elements, and we can deal with device events as with any other element on the page. This works well with reasonable numbers of elements, but things start to get bogged down when dealing with thousands of elements (or even hundreds depending on the browser).
Canvas provides an alternative means of drawing graphics. We can paint onto a canvas repeatedly without a memory penalty because the browser is not keeping track of individual elements, only a limited set of pixels. This allows us to push the limits on the number of graphic features drawn, but it comes with its own drawbacks.
The problem addressed here is that when drawing objects with canvas, there’s no support for detecting when the user clicks on (or touches) a rendered object. The solution adopted by many is to keep track of the geometries or bounding boxes of all the objects and to look for intersections with each event of interest. This works sufficiently well in some circumstances, but there are plenty of places where it fails.
In OpenLayers, for example, a user might have thousands of points on a map, all rendered with an arbitrary graphic (maybe a pushpin). Knowing the geometry or bounding boxes of the underlying points doesn’t necessarily help because intersections with a point geometry (in map coordinates) and a mouse position (in pixels) are exceedingly rare. Instead, the user really wants to get some interaction when their mouse intersects the rendered feature (e.g. the pushpin), not the original geometry.
A Solution
Since we really want to know when the pixel location of an event coincides with a feature rendered with canvas, we have to either calculate the geometry of the rendered feature (tough with a known symbolizer, impossible with an external graphic with transparency) or render the feature first and then query the canvas to see which pixels were painted.
The getImageData method on a canvas’ 2D context provides an easy way to query which pixels have been painted. If we were only interested in whether or not an event “hit” any rendered feature, all we’d have to do is check if the RGBA values for a pixel were non-zero. However, in our case, we want to know which specific feature was hit.
One solution is to translate feature identifiers into RGB values, and then to use a dedicated canvas to render features based on these translated identifiers. Then, when checking the response from getImageData, we can reverse the translation and turn RGB values back into feature identifiers.
Since we need to also know when an event misses all features, it makes sense to reserve a single color to represent no feature. Using hex notation for color values, we say that #000000 (black) represents no feature. So, a feature with an identifier of 8 would be represented by #000009. The color #000065 corresponds to feature identifier 100. #0f4241 corresponds to feature 1,000,000. And so on. This gives us 16,777,214 unique identifiers for features. That’s a pretty big number. You’d have to wait quite a while to transfer enough data from server to client to represent 16 million features. However, since we can’t be certain that someone won’t try it, we can also keep track of an overflow value. Keeping track of an overflow, we can represent over 16 million sequential feature identifiers by painting pixels on a canvas.
The Good
The good news is that this solution works. In OpenLayers, for each layer we have a display canvas. In addition, we can create a second “hit” canvas. And we don’t even have to append this second canvas to the DOM. Each time we draw to the display canvas, we can do a second draw to the hit canvas.
Say we’ve got a feature that can be identified by the number 14. That would correspond to a color of #000015. Imagine that this feature has a line geometry and that the user wants it rendered with a 2-pixel stroke. On our hit canvas, that would look like this: a thin black line  .
.
A closeup of the thin black line pixel data looks like this:
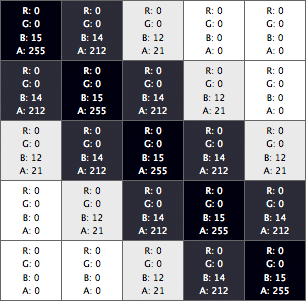
You can see that the feature identifier to pixel color translation works where the pixel is completely opaque (A: 255). That means a couple things. First, instead of rendering to our hit canvas with the user’s desired opacity values, we always want to render features completely opaque (setting context.globalAlpha = 1.0 on the hit canvas).
The second issue is a bit more troubling. Since canvas rendering is antialiased, we get alpha transparency in some pixels - the user asks for a 2-pixel stroke, but we don’t get two completely opaque, adjacent pixels normal to the line. This means if we stick with the user set stroke widths, narrow lines are very hard to hit. But that’s ok. We can consistently bump up the stroke width for our hit canvas. Increasing the stroke width by 2 pixels (context.lineWidth = userLineWidth + 2) and only considering hits where the alpha values returned by getImageData are 255 looks to work around this issue.
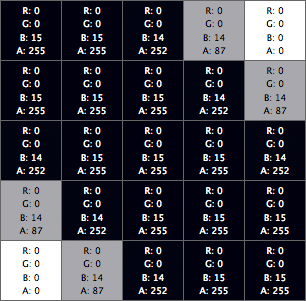
The closeup above shows pixel data for the hit canvas for a 4-pixel wide line. Since we get back what is approximately a 2-pixel wide, completely opaque line, we can translate RGB values into identifiers to determine which feature was hit. Not so bad.
The Bad
Unfortunately, there are some other issues with this method that are not so easy to work around. Above, I mentioned that the user might be using an arbitrary graphic to render points. To render pixels on our hit canvas that represent non-transparent pixels in a user supplied graphic requires a bit of work. What we want is pixels with specific RGB values on our hit canvas. What we’ve got is the URL for an image that should be used to represent the point.
In OpenLayers, when the user wants a point to be represented by an arbitrary image, we create a new Image object, set the src to the provided image URL, and then in onload we render that image to the display canvas. To support hit detection, we can also render the image to a (third) dedicated graphic canvas and then iterate through the pixels (returned by getImageData), drawing feature-identifiable colored pixels onto the hit canvas for each pixel that is not transparent in the graphic canvas. This means that if a user provides a URL for a rectangular pushpin image, we can detect when mouse or touch events coincide with the colored part of the image and ignore events coinciding with transparent pixels in the image.
This is already starting to get cumbersome. Rendering to three canvases, performance is still good with a reasonable number of features, but we’re making the browser do a lot of extra work.
The real problem with this approach is that it is limited to the same origin policy. The canvas keeps track of which pixels came from where, and when we call getImageData on a portion of a canvas where drawImage was called with an image from a different origin, we get a SECURITY_ERR error.
The solution to this actually simplifies things a bit. If we dispense with the requirement that we have to differentiate transparent from non-transparent pixels in the user provided image, we can simply draw a rectangle of the same size as the user supplied image on our hit canvas. With this alternative, we get false positives where image rectangles might overlap one another. Though the user tries to click on a lower visible feature, we mistakenly think they are clicking on a feature whose graphic extent overlaps the lower feature.
The Ugly
The false positives described above are acceptable, I think. With this type of hit detection, we get another type of false positive that is more unsettling. Due to antialiasing, where features intersect, we may get completely opaque pixels that don’t share the RGB values of either intersecting feature. Take for example this set of intersecting green and red lines: 
Looking at a closeup of the pixel data, the center pixel is completely opaque (A: 255), but has RGB values that differ from the two lines.
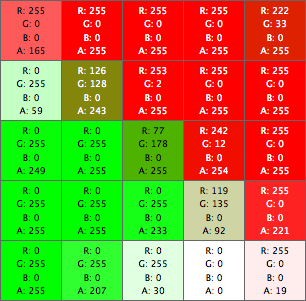
Using the solution described above, if the user clicked on this single center pixel, we would mistakenly think they clicked on a feature other than the ones rendered here. This isn’t a problem if the RGB values for the pixel in question don’t translate to a feature identifier that we know about, but it’s not hard to come up with situations where a real identifier is generated. For example, two features with identifiers 2 and 4 “look” like a feature with identifier 3 in a few pixels around their intersection point.
In real applications, when listening for click or touch events, we can hope this type of false positive is rare (a few pixels around the intersection of features with identifiers that surround another feature identifier in color space). An alternative to work around the issue is to look at a bigger block of pixels for each event. Since the situations that produce this type of false positive typically have color gradients, in addition to restricting hits to completely opaque pixels, we can restrict hits to areas with no color gradient. A bit of experimentation shows that using a 3x3 block of pixels is enough to avoid the most frequent false positives. We just have to check that neighboring pixels all have the same RGB values (the center “+” of pixels in the 3x3 block).
Wrap Up
In the end, I think using a dedicated hit canvas and doing feature identifier to color translations is a viable way to allow users to interact with rendered features on a canvas. This method is what we now do in OpenLayers (allowing us to do feature editing on mobile devices that don’t support SVG). The canvas renderer can still use some enhancements to avoid the issues described above, but it’s a nice start.