Topology Preserving Simplification
04 Mar 2014 CommentsThis is a reprint that was originally published as a Boundless blog post.
OpenLayers 3 aims to push the boundaries when it comes to rendering vector data in a browser. Whether you’re editing a stream network, exploring congressional district boundaries, or just viewing point markers on a world map, we want you to be able to see and interact with beautifully rendered vector data even when dealing with large, complex datasets. To achieve this, the library needs to be very efficient at simplifying geometries without sacrificing the visual integrity of the data.
When a geometry has many vertices per device pixel, it is best not to waste a user’s time by trying to draw every one of them. Developers typically try to solve this problem by simplifying polygons with an algorithm based on Douglas–Peucker (although Visvalingam has not completely been overlooked). However, these line simplification algorithms are not suitable for polygon simplification when topology needs to be preserved — meaning when geometry rules like “must not overlap” and “must not have gaps” need to be enforced.
Considering Douglas-Peucker
If, for example, you are rendering polygons that represent administrative boundaries, and your audience is going to be surprised to see gaps between adjacent boundaries, you’ll need to consider a simplification algorithm that preserves topology. The graphic below shows national borders simplified with a Douglas-Peucker–based algorithm at a few different tolerance levels.
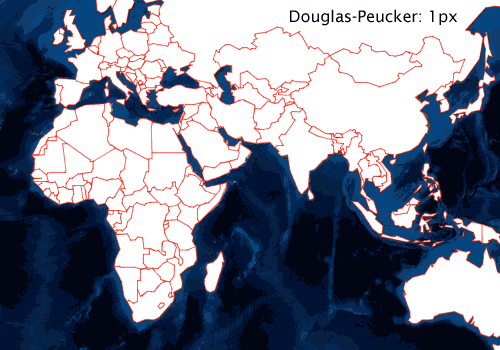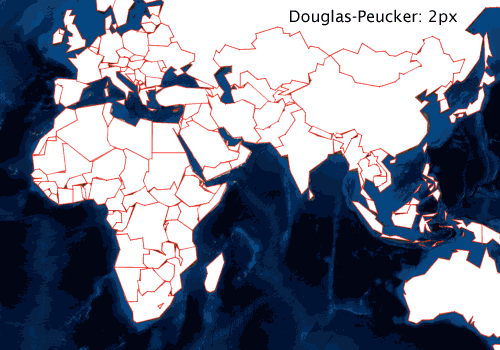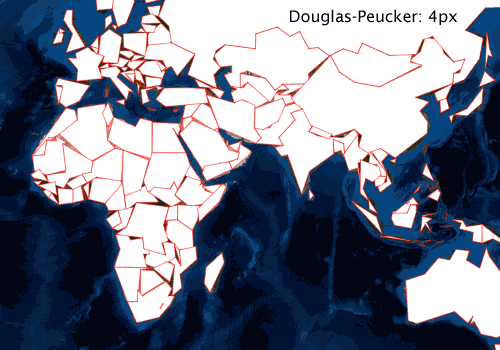
I’ll use units of device pixels when talking about simplification tolerance. While these are translated to map units before simplifying, it is easier to reason about pixels when discussing rendering. As shown above, simplification using Douglas-Peucker results in a visual loss of topology at the 2px tolerance level. At a 4px tolerance, the method is clearly unsuitable for simplification before rendering. Faced with these results, you might conclude that the method should just use a 1px tolerance or below and then move on.
An aside on frame budget
When animating things like map panning or zooming, having a constant frame rate prevents the viewer from experiencing stuttering map movements. On capable devices, sixty frames per second is a good goal, but it leaves a frame budget of only 16.7 milliseconds. Within that budget, you will need to access all features for rendering, calculate all symbolizers to be used, do any geometry simplification, and then do the actual drawing. The Douglas-Peucker simplification above takes about 35ms to run on a moderately “low resolution” set of features with a capable browser. Since this completely blows the target frame budget, simplification during animation is out of the question.
The answer, of course, is to cache the simplified geometries (or the draw instructions themselves) and use the cached results during animation. However, this presents a new problem. During animated zooming, simplified geometries that looked okay at the original resolution may show gaps and overlaps at a 2x or 4x higher resolution — this is sort of like what you see going from the 1px simplification to 4px in the graphic above.
Quantization-based simplification
So, to avoid extra work rendering visually insignificant vertices without artifacts produced by Douglas-Peucker, you’ll need to consider an algorithm that preserves topology.
Quantization is basically the process of taking a continuous (or large) set of values and mapping them to a discrete (or smaller) set of values. Rounding to the nearest integer is an example of quantization. The reason to consider quantization as the basis for geometry simplification is that this repeatable mapping of continuous to discrete values preserves topology - two geometries that share coordinate values before simplification will still share values after. As mentioned earlier, I’m concerned primarily with “must not overlap” and “must not have gaps” type topology rules. Quantization will change the topology in other ways (rings may no longer have area), but it will respect topology in this aspect: if adjacent geometries don’t have gaps before, they won’t after. Same goes for overlaps.
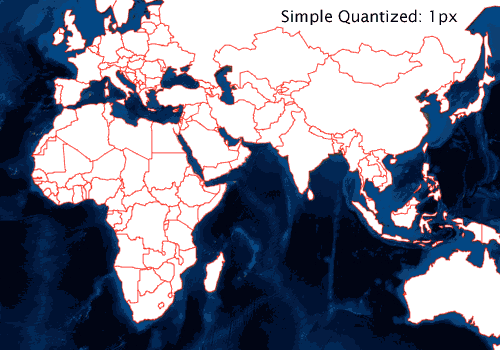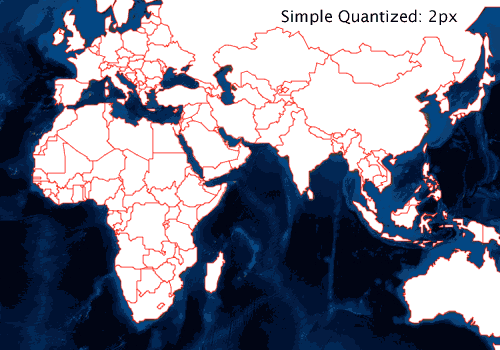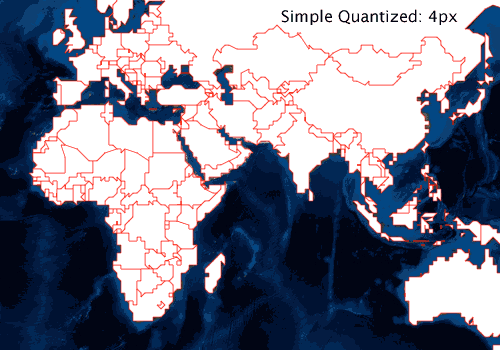
While quantization at the 4px tolerance level above generates undesirable results, the 1px and 2px levels look good. Quantization itself is a form of simplification. But we can take it a bit farther without doing much work. The simplification steps are basically these:
- quantize coordinate values given some tolerance
- drop duplicate and collinear points (when more than 2)
This quantization based simplification can be performed in a single pass over the original coordinate values. For similar data sets and tolerance, the method is considerably faster than Douglas-Peucker [1]. It is also clearly less aggressive at simplifying [2]. However, it accomplishes our goals. Quantization based simplification avoids rendering vertices that don’t have a significant visual impact while preserving the kind of topology we care about.
Quantization based simplification is itself rather simplistic. While it is possible to maintain topology with methods like Visvalingam’s line simplification, this requires that you have a known or fixed set of vertices before simplifying. This doesn’t work if you are progressively loading and rendering data or otherwise need the simplification process to be repeatable for a single geometry regardless of which other geometries it is rendered with.
See for yourself!
Take a look at the OpenLayers 3 vector rendering examples to see this topology preserving simplification in action — and let us know if you find any gaps or overlaps in adjacent polygons!
[1] Quantization-based simplification performed 2–7x faster than Douglas-Peucker on the same data sets with the same tolerance in unscientific benchmarks performed while writing this post.
[2] With a tolerance of 80,000m, the Douglas-Peucker method reduced the original number of vertices in the sample dataset by 70% while the quantization based method reduced the number by 27%. The 80,000m tolerance corresponds to about 2 pixels at zoom level 2 in the common XYZ tiling scheme.